


")
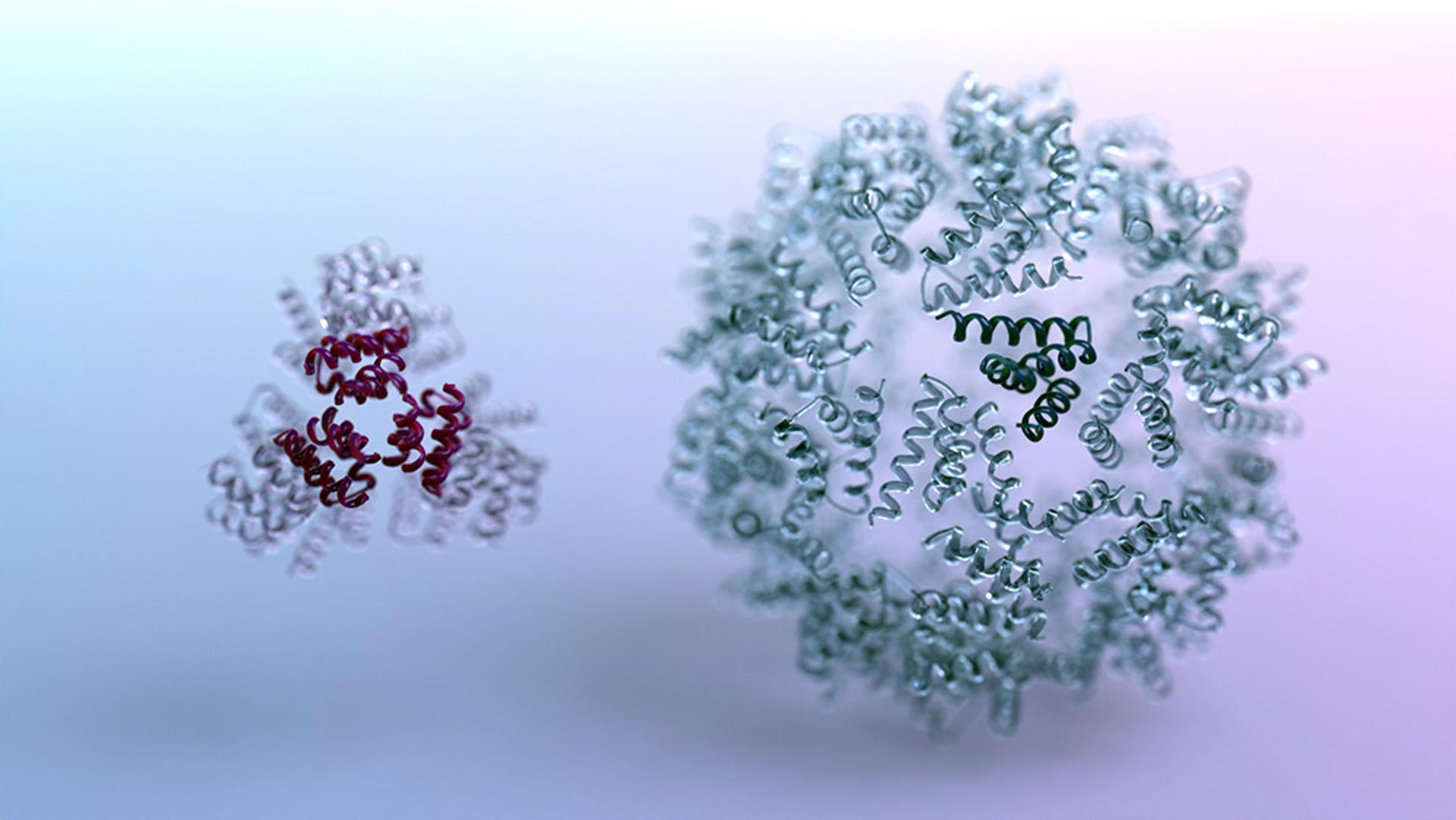
Un equipo de la Universidad de Washington ha desarrollado un software de diseño de proteínas basado en el aprendizaje por refuerzo, un tipo de aprendizaje automático en el que un programa aprende a tomar decisiones probando distintas acciones y recibiendo retroalimentación.
Un algoritmo de este tipo puede aprender a jugar al ajedrez, por ejemplo, probando millones de jugadas distintas que conducen a la victoria o la derrota en el tablero. La mecánica está diseñada para aprender de estas experiencias y mejorar, con el tiempo, en la toma de decisiones.
El programa ha sido capaz de diseñar cientos de proteínas más eficaces para generar anticuerpos útiles en ratones, lo que podría conducir a vacunas más potentes.
El método podría llevar a una nueva era en el diseño de proteínas y tener aplicaciones potenciales en el desarrollo de tratamientos más eficaces contra el cáncer y la creación de nuevos tejidos biodegradables.
Los científicos dieron al ordenador millones de moléculas sencillas de partida y el programa hizo 10.000 intentos de mejorar aleatoriamente cada una de ellas hacia un objetivo predefinido.
El ordenador alargó o dobló las proteínas de formas específicas hasta que aprendió a darles la forma deseada.
Como parte del estudio, los científicos fabricaron en el laboratorio cientos de proteínas diseñadas por la inteligencia artificial y confirmaron que muchas de las formas de proteínas creadas por el ordenador se hacían realidad en el laboratorio con una precisión atómicamente precisa.
El equipo se concentró en diseñar nuevas estructuras a escala nanométrica compuestas por muchas moléculas proteicas, lo que requirió diseñar tanto los propios componentes proteicos como las interfaces químicas que permiten el autoensamblaje de las nanoestructuras.












")

